Git: Guía completa para empezar desde cero
1. ¿Qué es Git y por qué existe?
Como habéis visto en el título del post, hoy vamos a hablar de Git.
Primero os quiero hablar de la historia de Git de forma breve:
Git surgió en 2005 de la mano de Linus Torvalds, el creador de Linux. La necesidad de un sistema de control de versiones surgió a raíz de la necesidad de gestionar el desarrollo del kernel de Linux, que en ese momento era un proyecto muy grande y con muchos colaboradores. En ese momento, el sistema de control de versiones que se utilizaba era BitKeeper, pero debido a problemas con la licencia, se decidió crear uno propio. Ya sabemos que los usuarios de Linux son muy dados a crear sus propias herramientas y más si no están de acuerdo con las existentes.
Una vez creado Git, se extendió rápidamente por la comunidad de desarrolladores y se convirtió en el sistema de control de versiones más utilizado en el mundo.
Pero antes ¿qué es un sistema de control de versiones o VCS? Un sistema de control de versiones es una herramienta que permite gestionar los cambios en el código fuente de un proyecto a lo largo del tiempo. Permite guardar diferentes versiones del código y volver a ellas en cualquier momento. Por ejemplo creo que todos hemos tenido las típicas carpetas con nombres como “proyecto_final_v2_DEFINITIVO” o “proyecto_final_v2_DEFINITIVO_AHORA_SI”. Git y los sistemas de control de versiones vienen a solucionar exactamente ese problema.

Una pregunta que me surgió al principio es qué alternativas hay a Git. Pues existen otros sistemas de control de versiones como SVN o Mercurial, pero Git se ha convertido en el estándar de la industria por su flexibilidad y rapidez.
La diferencia más importante es que SVN es un sistema centralizado mientras que Git es distribuido. Esto significa que en SVN hay un servidor central que almacena todo el código y en Git cada desarrollador tiene una copia completa del repositorio en su máquina. Esto hace que Git sea mucho más rápido y que puedas trabajar sin conexión.
Respecto a Mercurial me encontré un post muy bueno que los compara: describe Git como MacGyver (flexible, potente, construido de pequeñas piezas combinables) y Mercurial como James Bond (elegante, rápido, pero más rígido en su forma de funcionar). Si os interesa, os dejo el enlace: Git vs Mercurial: Please Relax.
Preguntas frecuentes
¿Necesito saber programar para usar Git? No. Git es una herramienta independiente del lenguaje. Puedes usarla con proyectos de Python, JavaScript, Java, o incluso para gestionar documentos de texto. Lo único que necesitas es una terminal.
¿Git y GitHub son lo mismo? No, para nada. Git es la herramienta que corre en tu ordenador. GitHub es una plataforma web donde puedes alojar tus repos. Es como la diferencia entre un documento de Word y Google Drive. Lo vemos más a fondo en el siguiente post.
¿Solo se usa en proyectos grandes? Para nada. Yo lo uso hasta en proyectos pequeños personales. En cuanto tienes más de un archivo y piensas en “volver atrás”, Git ya te es útil.
2. Los 3 estados de un archivo en Git
Cuando trabajamos con Git los archivos que creamos y modificamos pueden estar en 3 estados:
- Working Directory: Es el directorio donde trabajamos con los archivos.
- Staging Area: Es el área donde preparamos los cambios que queremos guardar.
- Repository: Es el repositorio donde guardamos los cambios de forma definitiva.
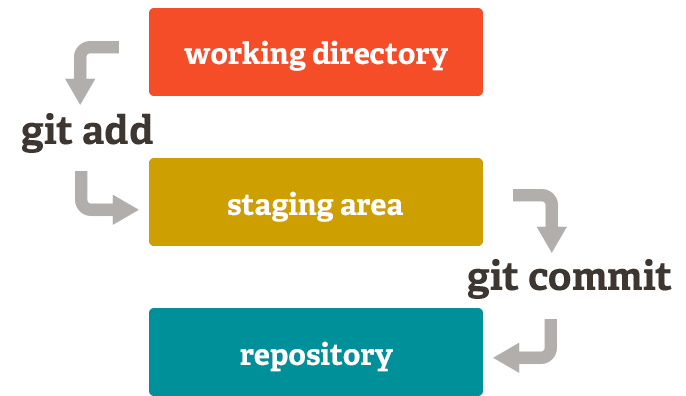
¿Y cómo pasamos de unos a otros?
Cuando creas un archivo nuevo o modificas uno existente, este se encuentra en el Working Directory. Para que Git lo tenga en cuenta, debemos añadirlo al Staging Area con el comando git add. Una vez que tenemos todo lo que queremos guardar en el Staging Area, podemos hacer un commit con el comando git commit. Este commit se guardará en el Repository.
En posteriores secciones veremos cómo revertir cambios en cada uno de estos estados sin perder trabajo.
Para que lo entendamos fácil: es como preparar la maleta de viaje. Tienes tu ropa en el suelo (Working Directory), la doblas y la metes en la maleta (Staging Area), y cierras la maleta (commit). Así será más fácil entender el flujo de trabajo de Git.
Preguntas frecuentes
¿Por qué existe el Staging Area? ¿No podría hacer el commit directamente? Puede parecer un paso de más, pero el Staging es lo que te da control fino sobre qué entra en cada commit. Imagina que has tocado 5 archivos pero solo quieres hacer commit de 2. Sin staging, tendrías que commitear todo o nada.
He hecho git add . y me arrepiento, ¿cómo lo deshago?
Con git restore --staged .. Esto saca todo del Staging sin borrar los cambios que has hecho en los archivos. No pierdes nada.
3. Configuración inicial
# Configura tu nombre y correo (aparecerán en cada commit tuyo)
git config --global user.name "Tu Nombre"
git config --global user.email "tu@email.com"
# Ver toda tu configuración actual
git config --listLo primero que tendremos que hacer antes de empezar a usar Git es configurar nuestro nombre y correo. Esto es importante porque quedará registrado en cada commit que hagamos y es lo que verán el resto de desarrolladores del proyecto.
Si ponemos --global, la configuración se aplicará a todos los repositorios de Git que tengamos en nuestro ordenador. Si no lo ponemos, la configuración solo se aplicará al repositorio actual. Esto es útil si quieres tener, por ejemplo, un email diferente para proyectos personales y proyectos del trabajo.
Por defecto el editor de texto que usa Git es Vim, que es un editor de terminal muy potente pero bastante complicado si no lo conoces. El meme de “cómo salir de Vim” en StackOverflow tiene millones de visitas por algo. Para cambiarlo a algo más amigable como VS Code, puedes usar este comando:
git config --global core.editor "code --wait"Este editor se abrirá en una nueva ventana cuando Git lo necesite (por ejemplo al hacer git commit sin el -m) y tendrás que cerrar esa pestaña para que Git sepa que has terminado.
Preguntas frecuentes
¿Es obligatorio poner nombre y email? Técnicamente Git te deja hacer commits sin configurar el nombre, pero no quedará bien en el historial y en algunos flujos de trabajo en equipo puede dar problemas. Es mejor hacerlo desde el primer momento.
¿Quedo pillado en Vim y no sé cómo salir?
Escribe :q! y pulsa Enter. Si quieres guardar los cambios antes de salir, escribe :wq. Y si quieres evitar este momento de pánico, configura VS Code como editor con el comando que hemos visto arriba.
4. Empezar un proyecto: git init y git clone
# Opción A: Crear un nuevo repositorio desde cero
git init nombre-proyecto
cd nombre-proyecto
# Opción B: Descargar un repositorio existente de GitHub
git clone https://github.com/usuario/repositorio.gitPara empezar un proyecto con Git tenemos dos opciones:
git init: Crea un nuevo repositorio desde cero en tu máquina. Puedes hacerlo en una carpeta nueva o en una que ya tengas con código.git clone: Descarga un repositorio existente desde un servidor remoto como GitHub. Es lo que harás la mayoría de las veces cuando te unes a un proyecto.
Ambas opciones son válidas dependiendo de la situación. Cuando hagas git init, Git creará una carpeta oculta llamada .git en tu proyecto. Esa es la carpeta que contiene todo el historial de cambios, la configuración del repositorio y toda la “magia” de Git. No tendrás que tocarla nunca, pero si la borras, pierdes el historial completo.
Por defecto el repositorio remoto al que apunta tu proyecto se llama origin. Es solo un alias, un apodo que Git le da a la URL del servidor remoto para que no tengas que escribirla entera cada vez.
Preguntas frecuentes
He hecho git init en la carpeta equivocada, ¿cómo lo deshago?
Simplemente borra la carpeta .git que se ha creado: rm -rf .git. Eso elimina el repositorio sin tocar tus archivos. Pero ójo, si ya tenías commits, los perderás todos.
¿Puedo clonar un repo privado? Sí, pero necesitas tener acceso. Lo más común es autenticarte con SSH o con un token de GitHub. Lo veremos en detalle en el siguiente post.
5. El .gitignore: lo que Git no debe ver
# Ejemplo de .gitignore
node_modules/
.env
*.log
dist/Un archivo que no debe faltar en nuestro repositorio es el .gitignore. Este archivo le dice a Git qué archivos no debe rastrear. Sin él, es muy fácil cometer errores que pueden tener consecuencias serias, como subir la carpeta node_modules (que puede pesar cientos de MB) o el archivo .env que contiene tus contraseñas y claves API.
Para encontrar plantillas ya hechas puedes usar gitignore.io o el repositorio oficial de GitHub. Si creas el repositorio directamente desde GitHub, también te da la opción de añadirlo automáticamente al crearlo.
Por lo general, los archivos que no queremos subir caen en estas categorías:
- Archivos de entorno y configuración sensible:
.env,config.local.js, archivos con contraseñas o claves API. - Dependencias: La carpeta
node_modules/,vendor/, etc. Estas se instalan con el gestor de paquetes, no se suben. - Archivos de logs: Cualquier archivo
.loggenerado en tiempo de ejecución. - Archivos del sistema operativo:
.DS_Store(macOS),Thumbs.db(Windows), etc. - Archivos de compilación o caché: Las carpetas
dist/,build/,.cache/, etc.
La regla de oro: crea el .gitignore antes de hacer el primer commit. Si añades algo que no debías después, arreglarlo es mucho más complicado.
Preguntas frecuentes
Ya subí el .env por error, ¿cómo lo elimino del historial?
Lo primero: cambia las credenciales que estaban en ese archivo porque ya son públicas. Después puedes usar git rm --cached .env para que Git deje de rastrearlo y añádelo al .gitignore. Si quieres borrar el historial completo es más complicado y requiere comandos como git filter-branch o herramientas como git-filter-repo.
¿Puedo ignorar un archivo que ya está siendo rastreado por Git?
Añadirlo al .gitignore no es suficiente una vez que Git ya lo rastrea. Tienes que hacer primero git rm --cached nombre-archivo para que Git deje de seguirlo, y luego añadirlo al .gitignore.
6. El ciclo de trabajo diario
6.1 Ver el estado del repositorio
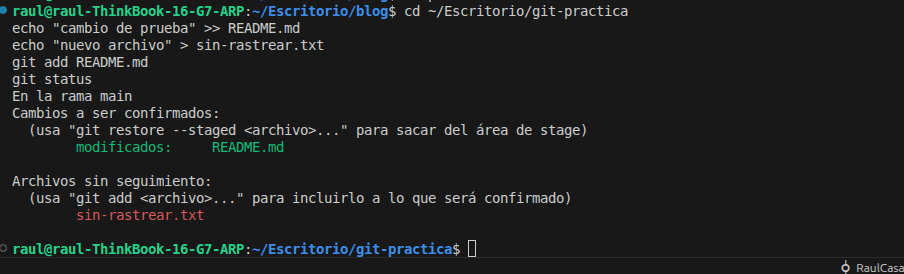
git statusgit status es probablemente el comando que más veces vas a usar en tu vida con Git. Y es que antes de hacer cualquier cosa es recomendable ejecutarlo para ver en qué estado están los archivos de tu repositorio. Te mostrará qué archivos han sido modificados, cuáles están en el Staging Area y cuáles no están siendo rastreados por Git.
Es muy importante entender los colores que nos muestra porque tienen un significado:
- Rojo: El archivo ha sido modificado o creado pero no está en el Staging Area.
- Verde: El archivo está en el Staging Area y listo para hacer el commit.
6.2 Añadir cambios al Staging
# Añadir un archivo concreto
git add archivo.txt
# Añadir todos los cambios
git add .
# Añadir partes de un archivo (modo interactivo)
git add -p archivo.txtUna vez que hemos visto el estado del repositorio y queremos añadir los cambios al Staging Area, usaremos el comando git add. Tenemos varias opciones:
git add archivo.txt: Añade un archivo concreto al Staging Area.git add .: Añade todos los archivos modificados al Staging Area. Cuidado con esto, puede que no quieras añadir todo.git add -p archivo.txt: Añade partes de un archivo de forma interactiva. Es útil cuando has hecho varios cambios en un mismo archivo pero solo quieres hacer commit de algunos.
En el día a día el más común es git add . pero como digo, hay que tener cuidado con lo que añadimos. Por eso es importante tener bien configurado el .gitignore.
6.3 Hacer un commit
# Commit con mensaje corto
git commit -m "feat: añadir formulario de login"
# Abrir el editor para escribir un mensaje largo y detallado
git commit
# Commit rápido de cambios ya rastreados (salta el git add)
git commit -am "fix: corregir typo en README"
# Modificar el último commit (mensaje o añadir un archivo olvidado)
git commit --amendUna vez que tenemos los cambios en el Staging Area, podemos hacer el commit. El commit es la acción de guardar los cambios en el repositorio. Para ello usaremos el comando git commit -m "mensaje". El mensaje del commit es muy importante porque nos ayudará a entender qué cambios se han hecho en ese commit. Por lo tanto, es muy importante que el mensaje sea descriptivo y conciso.
Cada commit tiene un identificador único llamado SHA, que es un hash de 40 caracteres. Este identificador es único para cada commit y nos permite identificarlo de forma única. Cuando haces git log puedes ver estos identificadores.
Respecto a los mensajes de commit, te recomiendo que uses la especificación de Conventional Commits. Esta especificación define un conjunto de reglas para los mensajes de commit que facilitan la lectura y el mantenimiento del historial de cambios. Por ejemplo:
feat:para nuevas funcionalidades.fix:para correcciones de errores.docs:para cambios en la documentación.chore:para tareas de mantenimiento.refactor:para refactorizaciones.
Por último, el commit --amend es muy útil cuando nos hemos olvidado de añadir un archivo o hemos cometido un error en el mensaje del commit. Este comando nos permite modificar el último commit sin crear uno nuevo. Pero cuidado, si ya has subido el commit al repositorio remoto, no es recomendable usar este comando ya que puede causar problemas a los demás desarrolladores.
6.4 Conectar con el remoto y subir cambios
# Ver a qué servidor remoto está conectado tu repo
git remote -v
# Subir cambios a la rama principal
git push origin main
# La primera vez que subes una rama nueva
git push -u origin mi-ramaCuando queremos subir nuestros cambios al repositorio remoto (GitHub en la mayoría de casos), usaremos el comando git push. Pero primero tenemos que asegurarnos de que nuestro repositorio local está conectado al repositorio remoto. Para ello usaremos el comando git remote -v que nos mostrará la URL del repositorio remoto.
El nombre origin es el nombre por defecto que se le da al repositorio remoto. Puedes cambiarlo, pero por convenio se suele dejar como origin. Cuando haces git push origin main le estás diciendo a Git: sube los cambios de la rama main al repositorio remoto llamado origin.
La primera vez que subes una rama nueva tienes que usar el flag -u para que Git sepa a qué rama del repositorio remoto tiene que apuntar. A partir de ahí, con solo poner git push ya sabe a dónde tiene que subir los cambios.
6.5 Descargar cambios del remoto
# Descargar Y mezclar cambios en tu rama actual (lo más común)
git pull
# Solo descargar sin mezclar (para inspeccionar antes)
git fetch
# Ver qué cambios trajo el fetch antes de mezclarlos
git diff origin/mainCuando trabajamos en equipo es muy probable que otros desarrolladores hayan subido cambios al repositorio remoto. Para descargar esos cambios usaremos el comando git pull. Este comando descarga los cambios del repositorio remoto y los mezcla con nuestra rama local. Es el equivalente a hacer git fetch + git merge en un solo paso.
Por otro lado, git fetch solo descarga los cambios pero no los mezcla. Esto es útil cuando quieres ver qué cambios han hecho otros antes de mezclarlos con los tuyos. Una vez que hayas revisado los cambios puedes hacer git merge para mezclarlos.
La regla de oro es: siempre haz git pull antes de empezar a trabajar por la mañana. Así te aseguras de tener siempre el código más actualizado y evitar conflictos innecesarios.
Preguntas frecuentes
He intentado hacer git push y me da error ¿por qué?
Lo más probable es que alguien haya subido cambios al remoto y tu repo local esté desactualizado. Haz primero git pull para descargar y mezclar esos cambios, y luego intenta el push otra vez.
¿Qué pasa si hago git pull y tengo cambios sin commitear?
Git te avisará y no dejará hacer el pull hasta que guardés o descartes tus cambios. Tienes dos opciones: hacer un commit de lo que llevas, o usar git stash para guardarlo temporalmente y aplicarlo después del pull.
¿Cuál es la diferencia real entre git pull y git fetch?
git fetch solo descarga la información del remoto pero no toca tu código. git pull hace lo mismo pero además mezcla los cambios automáticamente. Si quieres revisar antes de mezclar, usa git fetch + git diff origin/main.
7. Ver el historial
# Historial básico
git log
# Historial compacto (el más útil)
git log --oneline
# Historial con árbol de ramas visual
git log --oneline --graph --all
# Ver los cambios de un commit concreto
git show abc1234
# Ver quién cambió cada línea de un archivo y cuándo
git blame archivo.txtEl historial de commits es una de las partes más importantes de Git. Nos permite ver qué cambios se han hecho en el repositorio a lo largo del tiempo. Para ello usaremos el comando git log.
Pero la salida de git log puede ser un poco abrumadora al principio porque muestra mucha información. Es por eso que es recomendable usar el flag --oneline para ver el historial de forma más compacta. Y si además añadimos --graph --all podremos ver el árbol de ramas de forma visual en la terminal que queda bastante cool.

El git show nos permite ver los cambios de un commit concreto. Para ello tenemos que pasarle el SHA del commit. Por ejemplo git show abc1234.
Y por último, git blame es un comando muy útil para ver quién cambió cada línea de un archivo y cuándo. Es muy útil cuando quieres saber quién escribió una línea de código concreta.
Preguntas frecuentes
El git log me muestra demasiada información, ¿cómo lo filtro?
Puedes filtrar por autor (--author="Nombre"), por fecha (--since="2 weeks ago"), o buscar por mensaje (--grep="fix"). Por ejemplo: git log --oneline --author="Raul" --since="1 month ago".
¿Cómo vuelvo al código de un commit anterior sin perder lo que tengo ahora?
No uses git checkout a ciegas. Lo más seguro es crear una rama nueva desde ese commit: git switch -c rama-recuperacion abc1234. Así puedes ver cómo estaba el código en ese punto sin tocar tu rama actual.
8. Comparar cambios con git diff
# Ver cambios que NO están en staging aún
git diff
# Ver cambios que YA están en staging
git diff --staged
# Comparar dos commits
git diff abc1234 def5678
# Comparar con la rama main
git diff mainCon git diff podemos ver los cambios que hemos hecho en los archivos. La salida puede resultar un poco confusa al principio pero una vez que te acostumbras es muy útil:
- Las líneas en rojo son las que han sido eliminadas.
- Las líneas en verde son las que han sido añadidas.
La diferencia entre git diff y git diff --staged es que el primero muestra los cambios que están en el Working Directory y el segundo muestra los cambios que están en el Staging Area.
Te cuento un truco: tanto VS Code como muchos otros editores ya integran esta funcionalidad de forma visual con colores y marcadores en el gutter del editor. Si usas VS Code te recomiendo la extensión GitLens que te da mucha información extra sobre el historial de commits directamente en el editor.
Preguntas frecuentes
¿git diff no me muestra nada, por qué?
Si acabas de hacer git add, los cambios ya están en staging y git diff (sin flags) no muestra nada. Usa git diff --staged para ver lo que tienes en el área de preparación.
¿Cómo comparo mi rama con main antes de hacer el merge?
Con git diff main..mi-rama. Esto te muestra exactamente qué has cambiado tú respecto a main antes de fusionar, muy útil para hacer una revisión rápida.
9. Deshacer cosas sin pánico
9.1 Guardar cambios temporalmente
# Guardar cambios sin commitear para cambiar de tarea
git stash
# Recuperar los cambios guardados
git stash pop
# Ver la lista de cosas guardadas
git stash listUno de los escenarios más comunes cuando trabajas en equipo es que estás a medias de una tarea, cuando de repente te piden que arregles un bug urgente en otra rama. Con git stash puedes guardar temporalmente los cambios que estás haciendo sin necesidad de hacer un commit, cambiar de rama, arreglar el bug, y luego volver a tu tarea con git stash pop. Es como pausar la partida y retomarla más tarde.
9.2 Revertir cambios
# Descartar cambios de un archivo en working directory
git restore archivo.txt
# Sacar un archivo del staging (sin borrar los cambios)
git restore --staged archivo.txt
# Decirle a Git que deje de rastrear un archivo (sin borrarlo del disco)
git rm --cached archivo.txtEsta es la sección que más miedo da al principio porque cuando empiezas a usar Git, el miedo a hacer algo mal y perder trabajo es real. Pero tranquilo, Git tiene mecanismos para deshacer prácticamente cualquier cosa.
El comando más seguro para deshacer cambios es git restore. Este comando descarta los cambios de un archivo del Working Directory sin tocar el historial de commits. Es completamente reversible.
Si lo que quieres es sacar un archivo del Staging Area sin borrar los cambios, puedes usar git restore --staged. Y si lo que quieres es que Git deje de rastrear un archivo sin borrarlo del disco (muy útil cuando te has olvidado de añadirlo al .gitignore), puedes usar git rm --cached.
Preguntas frecuentes
He hecho un commit que no debería, ¿cómo lo deshago? Dependiendo de lo que quieras:
- Si el commit no lo has pusheado aún:
git reset --soft HEAD~1deshace el commit pero guarda los cambios en staging. - Si quieres deshacer el commit Y los cambios:
git reset --hard HEAD~1. Pero cuidado, esto sí borra los cambios del archivo. - Si ya lo has pusheado y no quieres reescribir el historial: usa
git revert HEADque crea un nuevo commit que deshace los cambios del anterior.
¿git restore borra mis cambios para siempre?
sí, git restore archivo.txt descarta los cambios no commiteados de ese archivo y no hay vuelta atrás. Por eso siempre es buena idea hacer un git status antes para ver exactamente qué vas a descartar.
10. Ramas: trabajar en paralelo
10.1 Crear y moverse entre ramas
# Ver todas las ramas locales
git branch
# Crear una rama nueva
git branch mi-funcionalidad
# Moverse a una rama (el comando moderno)
git switch mi-funcionalidad
# Crear y moverse a la vez
git switch -c mi-funcionalidad
# Borrar una rama (solo si ya está mergeada)
git branch -d mi-funcionalidad
# Borrar una rama a la fuerza
git branch -D mi-funcionalidadLas ramas son uno de los conceptos más importantes de Git. Una rama es básicamente una línea de desarrollo independiente que nos permite trabajar en nuevas funcionalidades sin afectar al código principal. La regla de oro en equipos es nunca trabajar directamente en main.
El flujo de trabajo más común es:
main: La rama principal. Siempre debe estar en estado funcional y listo para producción.develop: La rama de integración donde se unen todas las funcionalidades antes de ir amain.feature/nombre: La rama donde trabajas en una funcionalidad concreta.
El comando moderno para cambiar de rama es git switch. Es más claro e intuitivo que el clásico git checkout -b que verás en muchos tutoriales antiguos. Ambos funcionan igual, pero te recomiendo acostumbrarte al nuevo.

10.2 Fusionar ramas con git merge
# Situación: quieres fusionar "mi-funcionalidad" en "main"
git switch main
git merge mi-funcionalidadCuando hemos terminado de trabajar en una rama y queremos integrar los cambios en main, usaremos el comando git merge. Para ello primero tenemos que cambiarnos a la rama de destino (en este caso main) y luego hacer el merge de la rama que queremos integrar.
Hay dos tipos de merge:
- Fast-forward: Ocurre cuando la rama que se quiere integrar está directamente adelante de la rama destino, sin commits divergentes. Git simplemente mueve el puntero hacia adelante sin crear un commit de merge.
- Merge commit: Ocurre cuando hay commits divergentes entre las dos ramas. Git crea un commit nuevo que une los dos historiales.
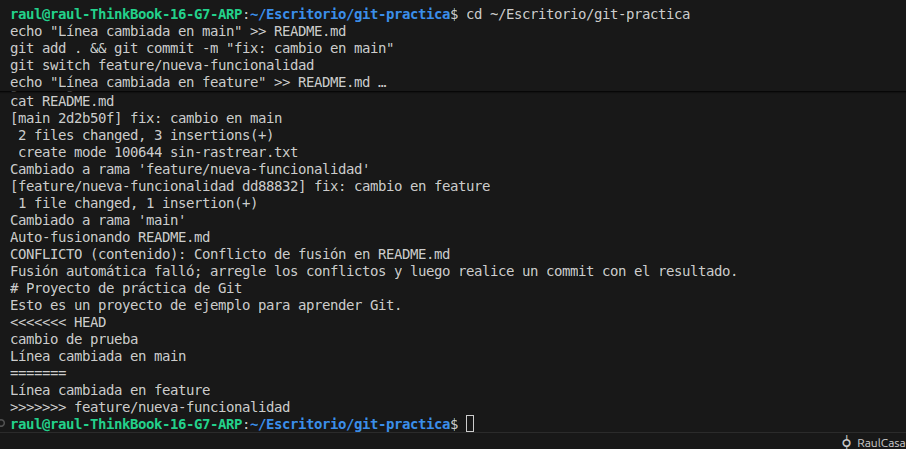
Y aquí es donde aparece el temido conflicto de merge. Un conflicto ocurre cuando dos ramas han modificado la misma línea del mismo archivo. En ese caso Git no sabe cuál de los dos cambios es el correcto y te lo indica en el archivo con estas marcas:
<<<<<<< HEAD
Esto es lo que hay en tu rama actual
=======
Esto es lo que hay en la rama que quieres integrar
>>>>>>> feature/nueva-funcionalidadPara resolver el conflicto tienes que abrir el archivo, elegir qué versión quieres quedarte (o combinar ambas), borrar las marcas que ha puesto Git y hacer un git add + git commit. No es tan complicado como parece una vez que lo haces un par de veces.
Preguntas frecuentes
He hecho merge y me he cargado código, ¿cómo lo deshago?
Si el merge ya tiene su commit, puedes revertirlo con git revert -m 1 HEAD. Si fue un fast-forward y aún no lo has pusheado, puedes usar git reset --hard HEAD~1 para volver al estado anterior.
¿Cuándo conviene usar --no-ff en el merge?
Cuando quieres que el historial deje constancia de que una funcionalidad vino de una rama separada. Si haces un fast-forward, los commits de la feature se mezclan con main y pierdes el contexto. Con --no-ff queda claro qué commits pertenecen a qué funcionalidad.
El conflicto parece muy grande, ¿por dónde empiezo?
Usa VS Code. Cuando abres un archivo con conflicto, te muestra los dos cambios en colores y botones para aceptar uno, el otro o ambos. Es mucho más cómodo que editar los <<<< a mano en la terminal.
11. Intro a GitHub (→ ver post completo de GitHub)
# Conectar tu repo local a uno de GitHub
git remote add origin https://github.com/tu-usuario/tu-repo.git
# Subir el código por primera vez
git push -u origin mainGit y GitHub son dos cosas distintas aunque mucha gente los confunde. Git es la herramienta de control de versiones que corre en tu ordenador. GitHub es la plataforma web que te permite alojar tus repositorios en la nube y colaborar con otros desarrolladores.
Para conectar tu repositorio local con GitHub tienes que:
- Crear un repositorio en GitHub (sin inicializarlo con README para evitar conflictos).
- Copiar la URL del repositorio.
- Conectarlo con tu repositorio local con
git remote add origin URL. - Subir el código con
git push -u origin main.
En el siguiente post veremos GitHub en profundidad: Pull Requests, Issues, GitHub Actions, etc.
Preguntas frecuentes
¿GitHub es de pago? Tiene plan gratuito que cubre perfectamente lo que necesitas para empezar: repos públicos y privados ilimitados, y colaboración con otros desarrolladores. Los planes de pago añaden cosas como más minutos de CI/CD o funcionalidades de empresa.
¿Puedo usar otro servicio que no sea GitHub? Claro. Existen alternativas como GitLab o Bitbucket. En esencia funcionan igual porque todos se basan en Git. La diferencia son las funcionalidades extra que ofrece cada uno. GitHub es el más popular en proyectos open source, pero GitLab tiene opciones muy buenas para auto-hospedar la plataforma.
12. Buenas prácticas y convenciones
Ya que hemos explicado los comandos, voy a aprovechar para darte unos consejos que te ahorrarán muchos dolores de cabeza:
- Commits pequeños y descriptivos: Un commit = una unidad lógica de trabajo. Evita los commits de “arreglos varios” o “cambios” a secas.
- Usa Conventional Commits: Como hemos visto antes, usar
feat:,fix:,docs:etc. hace el historial mucho más legible. - Nunca subas credenciales: Ni tokens, ni claves API, ni el
.env. Aunque el repo sea privado, mejor no acostumbrarse. git pullpor la mañana: Antes de empezar a trabajar, asegúrate de tener el código actualizado.- Usa ramas para todo:
maindebe estar siempre en un estado funcional. Todo el desarrollo se hace en ramas separadas. - Revisa antes de añadir: No hagas
git add .a ciegas. Haz primero ungit statuspara ver qué estás añadiendo.
Preguntas frecuentes
Nuestro equipo no usa Conventional Commits, ¿importa? No es obligatorio, pero sí que notaréis la diferencia cuando el proyecto lleva meses y el historial empieza a ser importante. Al menos acordad una convención interna, lo que sea, con tal de que todo el equipo lo siga de forma consistente.
¿Cuántos commits al día es lo normal? Depende del trabajo, pero personalmente prefiero hacer commits pequeños y frecuentes. No hay un número mágico. Lo importante es que cada commit represente una unidad lógica de trabajo, no un volcado de todo lo que has hecho en 3 horas.
13. Trucos avanzados y parámetros pro
Aquí es donde nos ponemos serios. Si has llegado hasta aquí y has entendido todo lo anterior, estos comandos y flags te van a resultar muy útiles en situaciones concretas. No son del día a día pero cuando los necesitas, los necesitas.
Flags útiles en comandos que ya conoces
# Ver solo los nombres de archivos modificados en un commit (sin el diff completo)
git show --name-only abc1234
# git log con fecha relativa y autor
git log --oneline --format="%h %ad %s" --date=relative
# Merge sin fast-forward: fuerza la creación de un commit de merge aunque no sea necesario
# Útil para mantener el historial de la rama visible
git merge --no-ff feature/mi-rama
# Merge con squash: aplana todos los commits de la rama en uno solo
# Muy limpio para pull requests pequeños
git merge --squash feature/mi-rama
# Stash solo de los archivos en staging (sin los que no has añadido)
git stash --staged
# Ver el diff de un archivo concreto entre dos ramas
git diff main feature/mi-rama -- archivo.py
# git blame con rango de líneas
git blame -L 10,25 archivo.pygit cherry-pick: coger un commit concreto de otra rama
git cherry-pick es uno de esos comandos que cuando lo descubres dices “¿dónde has estado toda mi vida?”. Te permite copiar un commit concreto de cualquier rama y aplicarlo a la rama en la que estás, sin tener que hacer un merge completo.
# Copiar un commit concreto a tu rama actual
git cherry-pick abc1234
# Cherry-pick de varios commits a la vez
git cherry-pick abc1234 def5678
# Cherry-pick sin crear el commit automáticamente (deja los cambios en staging)
git cherry-pick --no-commit abc1234Cuándo usarlo: imagina que tienes una rama feature/x con 10 commits, pero solo quieres traer uno de ellos a main (por ejemplo, un arreglo de bug urgente). En vez de mergear toda la rama entera, haces cherry-pick solo del commit que te interesa.
git restore --source: recuperar un archivo desde otra rama o commit
Esto es una joya que poca gente conoce. En lugar de copiar manualmente un archivo de una rama a otra, puedes pedirle a Git que lo recupere directamente:
# Recuperar un archivo tal como está en otra rama
git restore --source=feature/nueva-funcionalidad utils.py
# Recuperar un archivo tal como estaba en un commit concreto
git restore --source=abc1234 utils.py
# Recuperar TODOS los archivos tal como estaban en un commit (sin mover HEAD)
git restore --source=abc1234 .Muy útil cuando has borrado algo por error en tu rama y sabes que en otra rama está bien. En lugar de hacer un merge o un cherry-pick, recuperas solo el archivo que necesitas.
git checkout <hash> -- .: viajar a un punto del historial sin perder la rama
La sintaxis git checkout <hash> -- . copia el estado de todos los archivos de ese commit al Working Directory y al Staging, pero sin mover tu HEAD ni cambiar de rama. Es decir, viajas al pasado solo para ver o recuperar archivos, pero sigues en tu rama actual:
# Recuperar el estado de todos los archivos como estaban en ese commit
git checkout abc1234 -- .
# Recuperar solo un archivo concreto de ese commit
git checkout abc1234 -- src/utils/helpers.pyLa diferencia con git restore --source es básicamente de sintaxis: git checkout es el comando clásico y git restore --source es la versión moderna y más explícita que recomienda Git desde la versión 2.23. Ambos hacen lo mismo.
Ojo: después de hacer esto, tus archivos aparecerán en staging con los cambios del commit. Haz un
git statuspara ver qué ha cambiado y decide si quieres hacer commit de ello o no.
Bonus: comandos útiles que no hemos mencionado
# Ver un resumen de cuántas líneas has añadido/borrado por archivo
git diff --stat
# Buscar en qué commit se introdujo una cadena de texto concreta
git log -S "nombre_de_funcion" --oneline
# Ver el historial de UNA función concreta en un archivo
git log -L :nombre_funcion:archivo.py
# Deshacer el último commit pero mantener los cambios en staging
git reset --soft HEAD~1
# Limpiar archivos no rastreados del Working Directory (¡usa con cuidado!)
git clean -fd14. Cheat Sheet: todos los comandos de un vistazo
| Comando | ¿Para qué sirve? |
|---|---|
git config --global |
Configurar nombre y email |
git init |
Crear un repositorio nuevo |
git clone <url> |
Descargar un repositorio |
git status |
Ver el estado del repo |
git add <archivo> |
Añadir al staging |
git add . |
Añadir todo al staging |
git commit -m "..." |
Hacer un commit |
git commit --amend |
Modificar el último commit |
git push |
Subir cambios al remoto |
git pull |
Bajar y mezclar cambios |
git fetch |
Solo bajar (sin mezclar) |
git log --oneline |
Ver historial compacto |
git log --oneline --graph --all |
Ver árbol de ramas |
git show <sha> |
Ver detalle de un commit |
git diff |
Ver cambios sin staging |
git blame <archivo> |
Ver quién cambió cada línea |
git stash |
Guardar cambios temporalmente |
git stash pop |
Recuperar los cambios guardados |
git restore <archivo> |
Descartar cambios locales |
git restore --staged |
Sacar del staging |
git rm --cached |
Dejar de rastrear un archivo |
git branch |
Listar ramas |
git switch -c <rama> |
Crear y cambiar a una rama |
git merge <rama> |
Fusionar una rama |
git branch -d <rama> |
Borrar una rama |
git remote -v |
Ver servidores remotos |
14. Conclusión y recursos
Espero que este post te haya servido para entender los conceptos básicos de Git. Como aquí lo importante es practicar, te animo a que crees tu propio repositorio y empieces a hacer commits, ramas y merges. Al principio parece que tienes que recordar muchos comandos pero con el tiempo se vuelven automáticos.
En el siguiente post veremos GitHub en profundidad:¿Pull Requests? ¿Issues? ¿GitHub Actions? Todo eso y más.
Aquí os dejo algunos recursos que me han parecido muy útiles:
- Pro Git: El libro oficial de Git, gratuito y en español. Muy completo.
- Learn Git Branching: Una web interactiva para aprender las ramas de forma visual. Muy recomendable para entender el concepto de merge y rebase.
- Oh Shit, Git!: Una web con soluciones a los errores más comunes de Git contados con humor. Imprescindible tenerla a mano.