Multithreading
Una mirada filosófica al Multithreading
Introducción
Si estás leyendo esto, da igual que sepas o no lo que es el multithreading. Con este artículo quiero explicar con mis propias palabras qué es el multithreading y cómo funciona. Ya me enfrenté al problema de los filósofos en la escuela de 42 y quiero compartir mi experiencia con vosotros. Espero que os sirva de ayuda y que no os quedéis con dudas. Si tenéis alguna pregunta, no dudéis en contactarme.
¿Qué es el Multithreading?
Antes de sumergirnos en el problema filosófico, vamos a entender qué es el multithreading. Imagina que eres un cocinero profesional preparando una cena elaborada. Podrías cocinar cada plato de forma secuencial (un solo hilo), pero eso sería ineficiente. En lugar de eso, podrías tener varios procesos simultáneos: la sopa hirviendo en un fuego, la carne asándose en el horno, y tú cortando verduras.
En programación, un thread o hilo es como uno de esos procesos de cocina que puede ejecutarse de forma independiente. El multithreading es la capacidad de un programa para ejecutar varios hilos concurrentemente, permitiendo hacer varias tareas “al mismo tiempo”.
Los hilos son la medida más pequeña de ejecución en un programa. Cada hilo tiene su propio flujo de control, pero comparten el mismo espacio de memoria. Esto significa que pueden comunicarse entre sí de manera eficiente, pero también pueden entrar en conflicto si no se gestionan adecuadamente. En el caso de los filósofos, no se comunican directamente entre ellos mediante mensajes explícitos (como pipes o sockets), sino que interactúan indirectamente a través de los recursos compartidos (los tenedores) que residen en esa memoria común.
¿Qué es el problema de los filósofos?
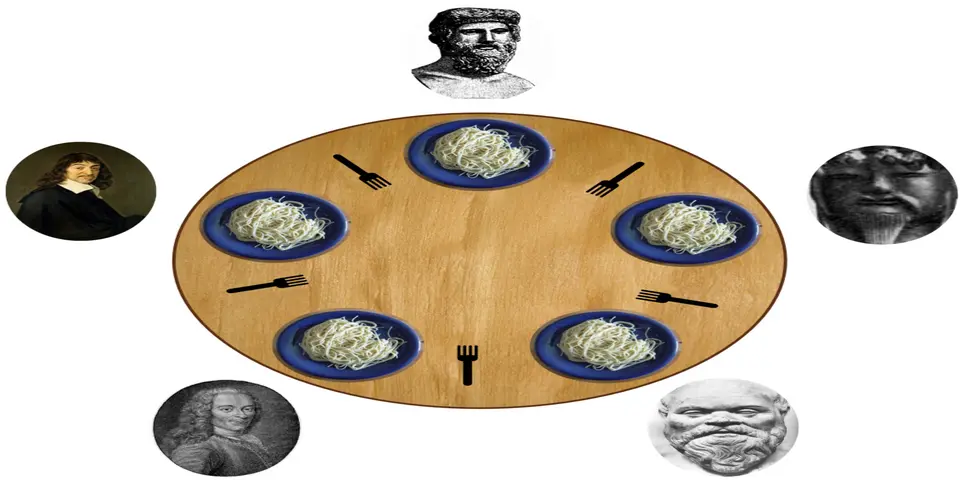
El problema de los filósofos te va a guiar por todos los problemas que el multithreading puede presentar. Desde deadlocks hasta data races no te preocupes si todavía no entiendes lo que son, al final del artículo tendrás una idea clara de lo que son y cómo evitarlos.
Pero vale cuál es el realmente el problema de los filósofos. En la implementación de 42 hay N filósofos donde N es un número mayor que 0. Cada filósofo tiene un tenedor a su izquierda y otro a su derecha. Para comer, necesita ambos tenedores. Y tú mi querido lector te estarás preguntando, ¿por qué 2 tenedores? No sé además que es un poco antihigiénico. Pero bueno, así es el problema. También tienes otros parámetros como el número de filósofos que ya hemos mencionado pero el número de tenedores es también el mismo número que el de filósofos. Así que si hay 5 filósofos, hay 5 tenedores. Tienes otros argumentos como el tiempo que tardan en morir, el tiempo que tardan en comer, el tiempo que tardan en dormir y por último un parámetro opcional que es la cantidad de veces que tienen que comer siendo este último un número mayor que 0. No lo he comentado pero el tiempo en este ejercicio se mide en milisegundos. Así que si un filósofo tarda 1000ms en comer, significa que tarda 1 segundo.
Todo esto da a lugar a que no todos los filósofos pueden comer al mismo tiempo. Si un filósofo coge el tenedor de su izquierda y el de su derecha, los demás filósofos no pueden comer. Pero claro que pasa si dos filósofos cogen el mismo tenedor a la vez. Pues que tendremos nuestro primer problema que se llama data racing que es lo que vamos a ver a continuación.
Conceptos clave en el multithreading
1. Recursos compartidos y data racing
Como hemos dicho los tenedores solo pueden ser usados por un filósofo a la vez. Pero claro con varios hilos es muy probable que el filósofo 1 intente usar el tenedor que está usando el filósofo 2 esto no se puede permitir. Entonces como podemos evitar que los hilos accedan a los tenedores al mismo tiempo? Pues la respuesta es con un mutex. Un mutex es un mecanismo de sincronización que permite que solo un hilo acceda a un recurso compartido a la vez. Es como si cada tenedor tuviera un candado y solo el filósofo que lo tiene en la mano puede usarlo.
Punto clave: Un mutex es atómico: solo un hilo puede bloquearlo a la vez, independientemente de cuántos lo intenten simultáneamente.
pthread_mutex_t tenedor_mutex[5]; // Array de mutexes para los tenedoresEn este ejemplo tenemos un array de mutexes que representan 5 filósofos y 5 tenedores. Cada tenedor tiene su propio mutex que se usa para bloquear el acceso al tenedor mientras un filósofo lo está usando. Entonces cuando un filósofo quiere usar un tenedor, primero bloquea el mutex correspondiente y luego lo libera cuando ha terminado de usarlo.
Pero por qué es tan importante los mutex. Bueno te voy a poner un ejemplo muy básico para que lo entiendas y lo puedas ejecutar tú mismo para ver la importancia.
#include <stdio.h>
#include <pthread.h>
#define NUM_THREADS 10
#define NUM_INCREMENTS 100000
int counter = 0; // variable compartida
void* increment(void* arg) {
for (int i = 0; i < NUM_INCREMENTS; ++i) {
counter++; // ⚠️ condición de carrera aquí
}
return NULL;
}
int main() {
pthread_t threads[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; ++i) {
pthread_create(&threads[i], NULL, increment, NULL);
}
for (int i = 0; i < NUM_THREADS; ++i) {
pthread_join(threads[i], NULL);
}
printf("Valor final del contador: %d (esperado: %d)\n", counter, NUM_THREADS * NUM_INCREMENTS);
return 0;
}En este ejemplo tenemos un contador que se incrementa 100000 veces por cada hilo. Si compilas y ejecutas el programa verás que el valor final del contador no es lo esperado. Pero por qué pasa esto? Porque al no estar protegido el hilo 1 puede leer el valor del contador antes de que el hilo 2 lo haya incrementado. Entonces el hilo 1 lee el valor del contador y lo incrementa pero el hilo 2 también lo hace al mismo tiempo. Entonces al final el valor del contador no es el esperado. Ya que las operaciones de sumar++ no son atómicas. Bueno Raúl y que significa que no sean atómicas? Si yo veo una línea de código que dice counter++ eso significa que el compilador va a hacer lo siguiente:
counter = counter + 1;Pero aunque tú estés viendo una sola línea de código, el compilador lo ve como varias líneas de código. En realidad lo que hace el compilador es algo como esto (si lo sé podría explicarlo en asembly pero tampoco quiero que te duermas y además no se assembly :D):
int temp = counter; // Lee el valor actual
temp = temp + 1; // Incrementa el valor
counter = temp; // Escribe el nuevo valorEsto significa que el compilador tiene que leer el valor del contador, incrementarlo y luego escribirlo de nuevo. Pero claro si el hilo 1 lee el valor del contador y antes de que el hilo 2 lo haya incrementado, el hilo 2 también lee el valor del contador y lo incrementa. Entonces al final el valor del contador no es el esperado. Todo esto porque el acceso a la variable compartida (el contador) no está protegido entonces los dos hilos pueden acceder a ella al mismo tiempo.
Si has ido siguiendo al explicación sabras que la solución a este problema es usar un mutex. Pero no tendriamos el mismo problema si el hilo1 y el hilo2 intentan acceder al mismo mutex a la vez?. Pues la respuesta es que no. El mutex es un mecanismo que sí es atómico esto quiere decir que no importa cuántos hilos intenten acceder al mutex al mismo tiempo, solo uno de ellos podrá acceder a él. Entonces si el hilo 1 bloquea el mutex, el hilo 2 tendrá que esperar a que el hilo 1 lo desbloquee antes de poder acceder a él. Lo que nos quita las condiciones de carrera. Bueno pues un problema menos ya solo te queda resolver tu propia vida y el resto del problema :D.
Solución para data races: Proteger el acceso a recursos compartidos con mutex garantiza que solo un hilo pueda modificarlo a la vez, evitando condiciones de carrera y asegurando la integridad de los datos.
Para verlo de una forma más visual, he creado estos pequeños gifs que puedes ver aquí:
Sin protección de mutex (data race):

Este gif muestra una animación paso a paso de una condición de carrera (data race). Dos hilos (Thread A y Thread B) intentan incrementar el mismo contador al mismo tiempo. Cada uno lee el valor original, lo incrementa y lo escribe de nuevo… pero como lo hacen simultáneamente, uno de los incrementos se pierde.
Aunque esperamos que el contador termine en 2, el valor final es solo 1. Esto muestra por qué counter++ no es una operación atómica y cómo el acceso concurrente sin sincronización puede causar errores impredecibles.
Con protección de mutex (acceso seguro):

En este segundo gif, se muestra la misma situación pero usando un mutex para proteger el acceso al contador. Cuando Thread A quiere incrementar el contador, primero bloquea el mutex. Thread B intenta hacer lo mismo, pero debe esperar hasta que Thread A termine y libere el mutex. De esta manera, las operaciones se ejecutan secuencialmente y el contador termina correctamente con el valor 2, evitando así la condición de carrera.
1.1. Semáforos: Control de Flujo con Capacidad
Hasta ahora hemos hablado de los mutexes para garantizar que solo un hilo acceda a un recurso a la vez. Pero, ¿qué pasa si tenemos un recurso que puede ser utilizado por un número limitado de hilos simultáneamente? Aquí es donde entran los semáforos.
Punto clave: Un semáforo es como un contador de permisos disponibles que pueden adquirir los hilos, permitiendo controlar cuántos hilos concurrentes pueden acceder a un recurso o grupo de recursos.
Imagina una sala de cine con capacidad limitada. No solo una persona puede entrar (como con un mutex), sino que pueden entrar 50 personas a la vez.
sem_t cine;
sem_init(&cine, 0, 50); // Inicializa el semáforo con 50 permisos
// Cuando un espectador quiere entrar
sem_wait(&cine); // Adquiere un permiso, el contador disminuye
// El espectador ve la película...
sem_post(&cine); // Libera el permiso cuando se va, el contador aumentaUn semáforo actúa como un contador de permisos. Cuando un hilo quiere usar el recurso, “adquiere” un permiso (con sem_wait), y el contador disminuye. Cuando termina, “libera” el permiso (con sem_post), y el contador aumenta. Si el contador llega a cero, los nuevos hilos deben esperar hasta que se libere un permiso.
Mutex vs. Semáforo
Un caso especial de semáforo es el semáforo binario, que se inicializa con un valor de 1. ¡Este se comporta exactamente como un mutex! Solo permite que un hilo adquiera el permiso a la vez. Sin embargo, un mutex a menudo ofrece características adicionales que lo hacen más robusto y específico para la exclusión mutua.
¿Cuándo usar uno u otro?
- Usa un mutex cuando necesites exclusividad absoluta para un recurso (ej., proteger una variable compartida o una sección crítica de código donde solo un hilo debe operar).
- Usa un semáforo cuando necesites controlar el acceso concurrente a un grupo de recursos limitados (ej., un pool de 10 conexiones a una base de datos o un buffer con capacidad limitada). También son útiles para sincronizar el orden de ejecución entre hilos.
Y después de explicarte por encima lo que son los semáforos te estarás preguntando bueno si los semáforos son tan buenos porque no los usamos siempre. Bueno la respuesta es que los semáforos son más complejos de implementar y pueden ser más propensos a errores si no se usan correctamente. Por eso en la mayoría de los casos es mejor usar un mutex. Y más en este caso ya que cada tenedor solo puede ser usado por un filósofo a la vez. Así que no necesitamos un semáforo para controlar el acceso a los tenedores. Y aunque a priori los semáforos parecen más utiles en este caso en concreto no lo son. Por eso coexisten los dos ya que habrá casos en los que un semáforo es más útil que un mutex y viceversa.
2. Deadlock (Bloqueo mutuo)
Nuestro mayor enemigo. Si cada filósofo toma el tenedor de su izquierda y espera el de la derecha, todos están bloqueados eternamente. Es como cuando quedas con tus amigos para decidir dónde comer y todos dicen “a mí me da igual, decidid vosotros”… y acabáis muriendo de hambre.
Punto clave: Un deadlock ocurre cuando dos o más hilos se bloquean eternamente, cada uno esperando por un recurso que otro tiene. En sistemas críticos, un deadlock puede causar fallos graves que requieren reiniciar todo el sistema.
Para entender mejor el concepto de deadlock, observa esta imagen:

En esta pequeña visualización se puede ver que cada filósofo ha cogido un tenedor (representado con la línea que va al triángulo). Esto crea una situación de bloqueo mutuo, donde cada filósofo está esperando al tenedor que tiene el filósofo a su derecha. Nadie puede comer y todos están atrapados en un ciclo de espera. Tendrías que evitar esta situación a toda costa.
Mi solución a este problema es simple aunque lo reconozco que no es la mejor. La solución es que cada filósofo par va a tener un pequeño delay a la hora de empezar a coger los tenedores. De esta manera si el filósofo 1 empieza a comer y el filósofo 2 no ha empezado a comer, el filósofo 2 no podrá coger el tenedor de la izquierda porque el filósofo 1 lo tiene cogido.
3. Liberación de recursos
Cuando un filósofo ha terminado de comer, debe soltar ambos tenedores. Esto es como cuando terminas de comer en un restaurante y dejas el plato vacío en la mesa. En programación, esto se traduce en liberar los mutexes que has bloqueado.
void soltar_tenedores() {
pthread_mutex_unlock(&tenedor_mutex[id]); // Suelta el tenedor izquierdo
pthread_mutex_unlock(&tenedor_mutex[(id + 1) % 5]); // Suelta el tenedor derecho
}Punto clave: Olvidar liberar los recursos es una de las causas más comunes de fugas de memoria y deadlocks en aplicaciones multihilo. Siempre desbloquea un mutex una vez que has terminado con él.
También es importante que se libere toda la memoria asignada dinámicamente (mediante malloc y funciones similares) al final del programa. Pero cuidado con esto ya que si usas Valgrind (una herramienta de detección de fugas de memoria) con un input en el que los filósofos deberían vivir indefinidamente, Valgrind hará que los filósofos mueran. Esto es debido a la ralentización que introduce Valgrind al monitorizar el programa. Así que si usas esta herramienta de depuración, ten en cuenta este comportamiento. De todas formas te recomiendo usarlo para detectar posibles fugas de memoria, pero no te preocupes si ves que los filósofos mueren prematuramente durante el análisis.
Otra solución para detectar problemas de concurrencia es usar la flag -fsanitize=thread en el makefile, que incluye la herramienta ThreadSanitizer para detectar data races:
CFLAGS = -Wall -Wextra -Werror -fsanitize=threadEsta herramienta de depuración también ralentizará la ejecución del programa, pero está específicamente diseñada para detectar problemas de concurrencia como data races, a diferencia de Valgrind que se enfoca más en problemas de memoria.
Otra cosa importante es el hecho de que el hilo principal del programa no puede morir antes que los demás hilos. Si el hilo principal muere, todos los demás hilos también mueren. Esto es como si el cocinero se va de la cocina y deja a los ayudantes solos. No van a saber qué hacer. Y este hilo principal se va a encargar de recoger a todos los demás hilos para liberar los recursos que han sido asignados.
¿Cómo lo aplicamos en el mundo real?
En sistemas modernos, el multithreading está por todas partes:
- Navegadores web: Cada pestaña es un proceso con múltiples hilos.
- Servidores: Atienden miles de peticiones concurrentes.
- Aplicaciones móviles: Mantienen la interfaz responsiva mientras hacen tareas en segundo plano.
- Bases de datos: Gestionan transacciones concurrentes mientras mantienen la integridad de los datos.
Ejemplo en JavaScript con Web Workers
JavaScript tradicionalmente era de un solo hilo, pero con Web Workers podemos ejecutar código en hilos separados:
// En el hilo principal
const worker = new Worker('tarea-intensa.js');
worker.onmessage = function(e) {
console.log('La tarea ha finalizado con resultado:', e.data);
};
worker.postMessage('Inicia el cálculo');
// En tarea-intensa.js (ejecutado en otro hilo)
onmessage = function(e) {
// Realizar cálculo intensivo...
const resultado = 42; // El sentido de la vida, según Douglas Adams
postMessage(resultado);
};Concurrencia en Bases de Datos
Las bases de datos enfrentan desafíos similares a los filósofos comensales. Cuando varios usuarios intentan modificar los mismos datos simultáneamente, pueden ocurrir problemas como:
- Lecturas sucias: Un usuario lee datos que otro usuario está modificando pero aún no ha confirmado.
- Actualizaciones perdidas: Similar a nuestro problema de data race, donde una actualización sobrescribe a otra.
Para solucionarlo, las bases de datos utilizan técnicas como:
-- Bloqueo explícito (similar a nuestros mutex)
BEGIN TRANSACTION;
SELECT * FROM cuentas WHERE id = 123 FOR UPDATE; -- Bloquea la fila
-- Hacer operaciones...
UPDATE cuentas SET saldo = saldo - 100 WHERE id = 123;
COMMIT; -- Libera el bloqueoPunto clave: Los sistemas de gestión de bases de datos implementan niveles de aislamiento de transacciones para evitar condiciones de carrera y deadlocks, permitiendo millones de operaciones concurrentes de forma segura.
Conclusión
El multithreading es como una orquesta donde cada músico (hilo) debe coordinarse perfectamente con los demás. Un solo error y toda la sinfonía puede derrumbarse. Y creeme que lo hará.
Reflexión final: La programación concurrente nos enseña que el verdadero desafío no está en ejecutar muchas tareas a la vez, sino en coordinarlas de manera que trabajen juntas sin interferirse. Como en la vida, el equilibrio es clave.
El problema de los filósofos nos enseña lecciones fundamentales sobre cómo diseñar sistemas concurrentes robustos.
Si te ha gustado este artículo, compártelo con tus amigos filósofos y programadores o con cualquiera que necesite leerlo. ¡Hasta la próxima!
Más Allá de lo Básico: Un Vistazo Rápido a Conceptos Avanzados
La programación concurrente es un campo vasto y complejo. Si bien los mutexes y semáforos son fundamentales, existen desafíos y soluciones más avanzadas que los ingenieros de sistemas utilizan para construir software robusto:
Inversión de Prioridad y Herencia de Prioridad
En sistemas donde los hilos tienen diferentes prioridades (como sistemas en tiempo real), puede ocurrir un fenómeno llamado inversión de prioridad. Esto sucede cuando un hilo de alta prioridad se ve obligado a esperar a un hilo de baja prioridad que tiene un recurso que necesita, y ese hilo de baja prioridad es a su vez interrumpido por un hilo de prioridad media.
Punto clave: Para mitigar la inversión de prioridad, algunos mutexes implementan la herencia de prioridad, elevando temporalmente la prioridad del hilo que posee el mutex a la del hilo de mayor prioridad que está esperando por él.
Tipos Especiales de Mutexes
No todos los mutexes son iguales. Las implementaciones modernas ofrecen variaciones:
- Errorcheck Mutexes: Útiles para depuración, detectan y reportan errores si un hilo intenta desbloquear un mutex que no posee o si intenta bloquear un mutex que ya tiene.
- Recursive Mutexes: Permiten que el mismo hilo bloquee el mutex varias veces. El mutex solo se libera completamente cuando se desbloquea el mismo número de veces que se bloqueó.
- Timed Mutexes: Permiten a un hilo intentar adquirir el mutex por un tiempo limitado, sin bloquearse indefinidamente si no lo consigue.
- Robust Mutexes: Diseñados para manejar el fallo inesperado del hilo que los posee. Si el hilo que tiene el mutex muere repentinamente, el robust mutex es liberado y marcado, alertando al siguiente hilo que lo adquiera que el recurso podría estar en un estado inconsistente.
Compartibilidad entre Procesos
Aunque los mutexes suelen usarse entre hilos del mismo proceso, algunos pueden configurarse para ser compartidos y sincronizar el acceso a recursos entre diferentes procesos, lo que resulta útil en arquitecturas de aplicaciones más complejas.
Spinlocks vs. Mutexes
Mientras que un mutex pone a dormir a un hilo que no puede adquirir el recurso (liberando la CPU), un spinlock hace que el hilo espere en un bucle ocupado (busy-wait).
// Ejemplo simplificado de un spinlock
while (!atomic_compare_exchange(&lock, 0, 1)) {
// Sigue intentando hasta conseguir el bloqueo
}Punto clave: Los spinlocks son más eficientes solo cuando el bloqueo es extremadamente corto, evitando el coste de cambio de contexto del sistema operativo.
Futex (Fast Userspace Mutex)
Una optimización de bajo nivel (específica de Linux) que permite a los mutexes y semáforos operar en el espacio de usuario la mayor parte del tiempo, recurriendo al kernel solo cuando un hilo realmente necesita ser puesto a dormir o despertado. Esto mejora significativamente el rendimiento en situaciones de baja contención.
Bueno y ahora sí que sí me despido. Espero que hayas disfrutado de este artículo y que hayas aprendido algo nuevo sobre el multithreading y el problema de los filósofos. Si tienes alguna pregunta o comentario, no dudes en ponerte en contacto conmigo. Por último te invito a que sigas investigando sobre el tema y que sigas aprendiendo. La programación concurrente es un campo fascinante y muy útil en la actualidad. Así que no dudes en seguir explorando y aprendiendo más sobre este tema.
Recursos adicionales
-
Philosophers Visualizer - Una herramienta interactiva para visualizar el problema de los filósofos comensales y entender mejor cómo funcionan los algoritmos de sincronización.
-
Wikipedia: Dining Philosophers Problem - El artículo de Wikipedia sobre el clásico problema de los filósofos comensales, con explicaciones detalladas y visualizaciones.
-
Thread Functions in C/C++ - Una guía completa sobre las funciones de hilos en C/C++, ideal para entender la implementación técnica de los conceptos discutidos en este artículo.



