Multithreading
A Philosophical Look at Multithreading
Introduction
If you are reading this, it doesn’t matter whether you know what multithreading is or not. With this article I want to explain in my own words what multithreading is and how it works. I already faced the problem for philosophers in the school of 42 and I want to share my experience with you. I hope it will help you and that you will not be left with any doubts. If you have any questions, don’t hesitate to contact me.
What is Multithreading?
Before we dive into the philosophical problem, let’s understand what multithreading is. Imagine you are a professional chef preparing an elaborate dinner. You could cook each dish sequentially (a single thread), but that would be inefficient. Instead, you could have several simultaneous processes: the soup boiling on a fire, the meat roasting in the oven, and you chopping vegetables.
In programming, a thread is like one of those kitchen processes that can run independently. Multithreading is the ability of a program to run multiple threads concurrently, allowing it to do several tasks ‘at the same time’.
Threads are the smallest measure of execution in a program. Each thread has its own control flow, but they share the same memory space. This means that they can communicate with each other efficiently, but they can also conflict if they are not managed properly. In the case of philosophers, they do not communicate directly with each other through explicit messages (such as pipes or sockets), but interact indirectly through the shared resources (the forks) that reside in that common memory.
What is the philosophers’ problem?
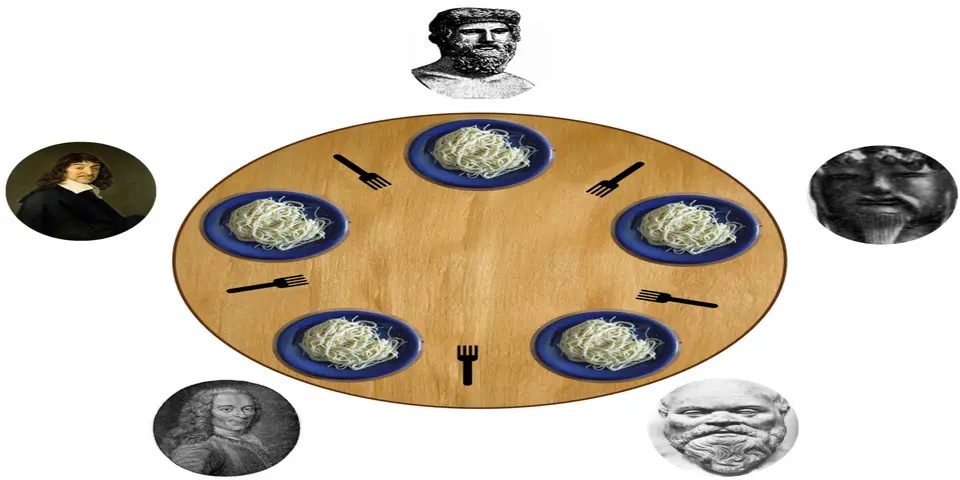
The philosopher’s problem will guide you through all the problems that multithreading can present. From deadlocks to data races, don’t worry if you still don’t understand what they are, by the end of the article you will have a clear idea of what they are and how to avoid them.
But what is really the problem of the philosophers? In the implementation of 42 there are N philosophers where N is a number greater than 0. Each philosopher has a fork on his left and a fork on his right. To eat, he needs both forks. And you my dear reader may be asking yourself, why 2 forks? I don’t know, besides it’s a bit unhygienic. But well, that’s the problem. You also have other parameters like the number of philosophers that we have already mentioned but the number of forks is also the same number as the number of philosophers. So if there are 5 philosophers, there are 5 forks. You have other arguments like the time they take to die, the time they take to eat, the time they take to sleep and finally an optional parameter which is the number of times they have to eat being a number greater than 0. I haven’t mentioned it but time in this exercise is measured in milliseconds. So if a philosopher takes 1000ms to eat, it means it takes 1 second.
All this means that not all philosophers can eat at the same time. If one philosopher takes the fork on his left and the fork on his right, the other philosophers cannot eat. But of course what happens if two philosophers take the same fork at the same time. Well, we will have our first problem which is called data racing which is what we are going to see next.
Key Concepts in Multithreading
1. Shared Resources and Data Racing
As we have said, the forks can only be used by one philosopher at a time. But of course with several threads it is very likely that philosopher 1 tries to use the fork that philosopher 2 is using and this cannot be allowed. So how can we prevent threads from accessing the forks at the same time? Well, the answer is with a mutex. A mutex is a synchronization mechanism that allows only one thread to access a shared resource at a time. It’s like each fork had a lock and only the philosopher who has it in his hand can use it.
Key point: A mutex is atomic: only one thread can lock it at a time, regardless of how many try simultaneously.
pthread_mutex_t fork_mutex[5]; // Array of mutexes for the forksIn this example we have an array of mutexes that represent 5 philosophers and 5 forks. Each fork has its own mutex that is used to block access to the fork while a philosopher is using it. So when a philosopher wants to use a fork, he first locks the corresponding mutex and then unlocks it when he is done using it.
But why are mutexes so important? Well, I’m going to give you a very basic example so you can understand it and run it yourself to see the importance.
#include <stdio.h>
#include <pthread.h>
#define NUM_THREADS 10
#define NUM_INCREMENTS 100000
int counter = 0; // shared variable
void* increment(void* arg) {
for (int i = 0; i < NUM_INCREMENTS; ++i) {
counter++; // ⚠️ race condition here
}
return NULL;
}
int main() {
pthread_t threads[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; ++i) {
pthread_create(&threads[i], NULL, increment, NULL);
}
for (int i = 0; i < NUM_THREADS; ++i) {
pthread_join(threads[i], NULL);
}
printf("Final counter value: %d (expected: %d)\n", counter, NUM_THREADS * NUM_INCREMENTS);
return 0;
}In this example we have a counter that is incremented 100000 times by each thread. If you compile and run the program you will see that the final value of the counter is not what you expected. But why does this happen? Because since it’s not protected, thread 1 can read the counter value before thread 2 has incremented it. So thread 1 reads the counter value and increments it but thread 2 also does the same at the same time. So in the end the counter value is not what we expected. Since the ++ operations are not atomic. Well Raul and what does it mean that they are not atomic? If I see a line of code that says counter++ that means the compiler is going to do the following:
counter = counter + 1;But even though you are seeing a single line of code, the compiler sees it as several lines of code. Actually what the compiler does is something like this (yes I know I could explain it in assembly but I don’t want you to fall asleep and besides I don’t know assembly :D):
int temp = counter; // Read the current value
temp = temp + 1; // Increment the value
counter = temp; // Write the new valueThis means that the compiler has to read the counter value, increment it and then write it back. But of course if thread 1 reads the counter value and before thread 2 has incremented it, thread 2 also reads the counter value and increments it. So in the end the counter value is not what we expected. All this because the access to the shared variable (the counter) is not protected so both threads can access it at the same time.
If you have been following the explanation you will know that the solution to this problem is to use a mutex. But wouldn’t we have the same problem if thread1 and thread2 try to access the same mutex at the same time? Well, the answer is no. The mutex is a mechanism that is atomic, which means that no matter how many threads try to access the mutex at the same time, only one of them will be able to access it. So if thread 1 locks the mutex, thread 2 will have to wait for thread 1 to unlock it before it can access it. This eliminates race conditions. Well, one problem less, now you only have to solve your own life and the rest of the problem :D.
Solution for data races: Protecting access to shared resources with mutex ensures that only one thread can modify it at a time, avoiding race conditions and ensuring data integrity.
To see it in a more visual way, I have created these small gifs that you can see here:
Without mutex protection (data race):

This gif shows a step-by-step animation of a race condition (data race). Two threads (Thread A and Thread B) try to increment the same counter at the same time. Each one reads the original value, increments it and writes it back… but since they do it simultaneously, one of the increments is lost.
Although we expect the counter to end at 2, the final value is only 1. This shows why counter++ is not an atomic operation and how concurrent access without synchronization can cause unpredictable errors.
With mutex protection (safe access):

In this second gif, the same situation is shown but using a mutex to protect access to the counter. When Thread A wants to increment the counter, it first locks the mutex. Thread B tries to do the same, but must wait until Thread A finishes and releases the mutex. This way, the operations are executed sequentially and the counter correctly ends with the value 2, thus avoiding the race condition.
1.1. Semaphores: Flow Control with Capacity
So far we have talked about mutexes to ensure that only one thread accesses a resource at a time. But what if we have a resource that can be used by a limited number of threads simultaneously? This is where semaphores come in.
Key point: A semaphore is like a counter of available permits that threads can acquire, allowing control of how many concurrent threads can access a resource or group of resources.
Imagine a movie theater with limited capacity. Not only one person can enter (as with a mutex), but 50 people can enter at the same time.
sem_t cinema;
sem_init(&cinema, 0, 50); // Initialize the semaphore with 50 permits
// When a viewer wants to enter
sem_wait(&cinema); // Acquire a permit, the counter decreases
// The viewer watches the movie...
sem_post(&cinema); // Release the permit when leaving, the counter increasesA semaphore acts as a permit counter. When a thread wants to use the resource, it “acquires” a permit (with sem_wait), and the counter decreases. When it finishes, it “releases” the permit (with sem_post), and the counter increases. If the counter reaches zero, new threads must wait until a permit is released.
Mutex vs. Semaphore
A special case of semaphore is the binary semaphore, which is initialized with a value of 1. This behaves exactly like a mutex! It only allows one thread to acquire the permit at a time. However, a mutex often offers additional features that make it more robust and specific for mutual exclusion.
When to use one or the other?
- Use a mutex when you need absolute exclusivity for a resource (e.g., protecting a shared variable or a critical section of code where only one thread should operate).
- Use a semaphore when you need to control concurrent access to a group of limited resources (e.g., a pool of 10 database connections or a buffer with limited capacity). They are also useful for synchronizing the execution order between threads.
And after explaining what semaphores are, you’ll be asking yourself well if semaphores are so good why don’t we always use them. Well, the answer is that semaphores are more complex to implement and can be more prone to errors if not used correctly. That’s why in most cases it’s better to use a mutex. And more in this case since each fork can only be used by one philosopher at a time. So we don’t need a semaphore to control access to the forks. And although semaphores may seem more useful at first, in this specific case they are not. That’s why both coexist since there will be cases where a semaphore is more useful than a mutex and vice versa.
2. Deadlock (Mutual Blocking)
Our greatest enemy. If each philosopher takes the fork on his left and waits for the one on the right, they are all blocked forever. It’s like when you meet with your friends to decide where to eat and everyone says “I don’t care, you guys decide”… and you all end up dying of hunger.
Key point: A deadlock occurs when two or more threads block eternally, each waiting for a resource that another has. In critical systems, a deadlock can cause serious failures that require restarting the entire system.
To better understand the concept of deadlock, look at this image:

In this small visualization you can see that each philosopher has taken a fork (represented by the line going to the triangle). This creates a mutual blocking situation, where each philosopher is waiting for the fork that the philosopher on his right has. Nobody can eat and everyone is trapped in a waiting cycle. You would have to avoid this situation at all costs.
My solution to this problem is simple although I admit it’s not the best. The solution is that each even philosopher will have a small delay when starting to take the forks. This way if philosopher 1 starts eating and philosopher 2 hasn’t started eating, philosopher 2 won’t be able to take the left fork because philosopher 1 has it.
3. Resource Release
When a philosopher has finished eating, he must drop both forks. This is like when you finish eating in a restaurant and leave the empty plate on the table. In programming, this translates to releasing the mutexes you have locked.
void release_forks() {
pthread_mutex_unlock(&fork_mutex[id]); // Release the left fork
pthread_mutex_unlock(&fork_mutex[(id + 1) % 5]); // Release the right fork
}Key point: Forgetting to release resources is one of the most common causes of memory leaks and deadlocks in multithreaded applications. Always unlock a mutex once you are done with it.
It is also important that all dynamically allocated memory (through malloc and similar functions) is freed at the end of the program. But be careful with this because if you use Valgrind (a memory leak detection tool) with an input where the philosophers should live indefinitely, Valgrind will make the philosophers die. This is due to the slowdown that Valgrind introduces when monitoring the program. So if you use this debugging tool, keep this behavior in mind. Anyway, I recommend using it to detect possible memory leaks, but don’t worry if you see that the philosophers die prematurely during the analysis.
Another solution to detect concurrency problems is to use the -fsanitize=thread flag in the makefile, which includes the ThreadSanitizer tool to detect data races:
CFLAGS = -Wall -Wextra -Werror -fsanitize=threadThis debugging tool will also slow down the execution of the program, but it is specifically designed to detect concurrency problems like data races, unlike Valgrind which focuses more on memory problems.
Another important thing is the fact that the main thread of the program cannot die before the other threads. If the main thread dies, all other threads also die. This is like if the cook leaves the kitchen and leaves the assistants alone. They won’t know what to do. And this main thread will be in charge of collecting all the other threads to free the resources that have been allocated.
How do we apply it in the real world?
In modern systems, multithreading is everywhere:
- Web browsers: Each tab is a process with multiple threads.
- Servers: They serve thousands of concurrent requests.
- Mobile applications: They keep the interface responsive while doing background tasks.
- Databases: They manage concurrent transactions while maintaining data integrity.
Example in JavaScript with Web Workers
JavaScript was traditionally single-threaded, but with Web Workers we can execute code in separate threads:
// In the main thread
const worker = new Worker('intensive-task.js');
worker.onmessage = function(e) {
console.log('The task has finished with result:', e.data);
};
worker.postMessage('Start the calculation');
// In intensive-task.js (executed in another thread)
onmessage = function(e) {
// Perform intensive calculation...
const result = 42; // The meaning of life, according to Douglas Adams
postMessage(result);
};Concurrency in Databases
Databases face challenges similar to the dining philosophers. When multiple users try to modify the same data simultaneously, problems can occur such as:
- Dirty reads: A user reads data that another user is modifying but has not yet confirmed.
- Lost updates: Similar to our data race problem, where one update overwrites another.
To solve this, databases use techniques like:
-- Explicit locking (similar to our mutexes)
BEGIN TRANSACTION;
SELECT * FROM accounts WHERE id = 123 FOR UPDATE; -- Lock the row
-- Do operations...
UPDATE accounts SET balance = balance - 100 WHERE id = 123;
COMMIT; -- Release the lockKey point: Database management systems implement transaction isolation levels to avoid race conditions and deadlocks, allowing millions of concurrent operations safely.
Conclusion
Multithreading is like an orchestra where each musician (thread) must coordinate perfectly with the others. A single error and the entire symphony can collapse. And believe me, it will.
Final reflection: Concurrent programming teaches us that the real challenge is not in executing many tasks at once, but in coordinating them so that they work together without interfering with each other. As in life, balance is key.
The philosophers’ problem teaches us fundamental lessons about how to design robust concurrent systems.
Beyond the Basics: A Quick Look at Advanced Concepts
Concurrent programming is a vast and complex field. While mutexes and semaphores are fundamental, there are more advanced challenges and solutions that systems engineers use to build robust software:
Priority Inversion and Priority Inheritance
In systems where threads have different priorities (like real-time systems), a phenomenon called priority inversion can occur. This happens when a high-priority thread is forced to wait for a low-priority thread that has a resource it needs, and that low-priority thread is in turn interrupted by a medium-priority thread.
Key point: To mitigate priority inversion, some mutexes implement priority inheritance, temporarily raising the priority of the thread that owns the mutex to that of the highest priority thread waiting for it.
Special Types of Mutexes
Not all mutexes are equal. Modern implementations offer variations:
- Errorcheck Mutexes: Useful for debugging, they detect and report errors if a thread tries to unlock a mutex it doesn’t own or if it tries to lock a mutex it already has.
- Recursive Mutexes: Allow the same thread to lock the mutex multiple times. The mutex is only completely released when it is unlocked the same number of times it was locked.
- Timed Mutexes: Allow a thread to try to acquire the mutex for a limited time, without blocking indefinitely if it doesn’t get it.
- Robust Mutexes: Designed to handle the unexpected failure of the thread that owns them. If the thread that has the mutex dies suddenly, the robust mutex is released and marked, alerting the next thread that acquires it that the resource might be in an inconsistent state.
Shareability between Processes
Although mutexes are usually used between threads of the same process, some can be configured to be shared and synchronize access to resources between different processes, which is useful in more complex application architectures.
Spinlocks vs. Mutexes
While a mutex puts a thread to sleep that cannot acquire the resource (freeing the CPU), a spinlock makes the thread wait in a busy loop (busy-wait).
// Simplified example of a spinlock
while (!atomic_compare_exchange(&lock, 0, 1)) {
// Keep trying until getting the lock
}Key point: Spinlocks are more efficient only when the lock is extremely short, avoiding the cost of operating system context switching.
Futex (Fast Userspace Mutex)
A low-level optimization (specific to Linux) that allows mutexes and semaphores to operate in user space most of the time, resorting to the kernel only when a thread actually needs to be put to sleep or woken up. This significantly improves performance in low contention situations.
Well, and now I really say goodbye. I hope you enjoyed this article and learned something new about multithreading and the philosophers’ problem. If you have any questions or comments, don’t hesitate to contact me. Finally, I invite you to keep researching the topic and keep learning. Concurrent programming is a fascinating and very useful field nowadays. So don’t hesitate to keep exploring and learning more about this topic.
Additional Resources
-
Philosophers Visualizer - An interactive tool to visualize the dining philosophers problem and better understand how synchronization algorithms work.
-
Wikipedia: Dining Philosophers Problem - The Wikipedia article about the classic dining philosophers problem, with detailed explanations and visualizations.
-
Thread Functions in C/C++ - A complete guide on thread functions in C/C++, ideal for understanding the technical implementation of the concepts discussed in this article.